
Trong bài test bên này, mình sẽ thử chạy GPT-OSS 120B thông qua LMStudio để tiện so sánh với bài test trước tương tự chạy trên Macbook M2 Max 96GB RAM cho mọi người dễ hình dung. Cả Ryzen AI Max+ và bản thân chiếc Z13 đều là những chiếc máy di động, do đó mình sẽ test ở tình huống không cắm điện chỉ chạy pin tương tự như Macbook lẫn có cắm điện và một số tùy chỉnh tối ưu để đẩy nó tới giới hạn.
Cho bạn nào lỡ quên các thông số khi test một model chạy local trên một máy, dưới đây là một số điểm cần quan tâm.
Xem một model chạy trên máy tính thì cần quan tâm điểm nào
Ở góc độ đơn giản nhất, khi mình chat với một con Chatbot thì mình cần nó trả lời xong càng nhanh càng tốt. Đó là mục tiêu cuối cùng. Đối với các model hiện tại, độ “thông minh” có xu hướng gắn với model reasoning (GPT-OSS là một model như thế) thì thời gian này nó lâu hơn LLM cơ bản chút do cần phải mất thời gian cho nó suy nghĩ, lên phương án nhiều bước rồi mới bắt đầu sinh ra chữ trả lời chúng ta.
- Tốc độ tạo token (Tokens per Second – t/s). Chỉ số này đo lường số lượng token (đơn vị từ hoặc ký tự) mà mô hình sản sinh ra mỗi giây sau khi đã xử lý xong yêu cầu đầu vào. Nó là thước đo cốt lõi cho tốc độ sinh văn bản và ảnh hưởng trực tiếp đến thời gian chờ đợi của người dùng để nhận được câu trả lời hoàn chỉnh.
- Thời gian đến token đầu tiên (Time to First Token – TTFT): đây cũng là một con số quan trọng, phản ánh độ trễ từ khi gửi yêu cầu đến khi nhận được ký tự phản hồi đầu tiên. TTFT càng thấp thì càng tạo cảm giác mô hình nhạy và phản ứng tức thì.
- Thời gian tải mô hình (Model Load Time): đây là khoảng thời gian cần thiết để nạp các trọng số từ ổ cứng vào bộ nhớ RAM và VRAM. Dù là nó chỉ chạy một lần khi bắt đầu sử dụng model nhưng dĩ nhiên, nó cũng ảnh hưởng tới trải nghiệm của người dùng.
- Mức sử dụng RAM và VRAM / GPU: cái này thì tất yếu rồi. Mức sử dụng RAM ảnh hưởng đến khả năng đa nhiệm của toàn bộ hệ thống còn VRAM (bộ nhớ GPU) quyết định bao nhiêu phần của mô hình có thể được tăng tốc bởi card đồ họa. Một mô hình quá lớn không vừa với VRAM sẽ chạy chậm hơn đáng kể.
Kết quả chạy các tác vụ AI từ đơn giản tới phức tạp ở chế độ chỉ pin
Mình thử chạy các tác vụ từ cơ bản tới nâng cao, bao gồm các phép so sánh đơn giản, các logic ràng buộc đòi hỏi tính nhất quán trong suy luận của AI, yêu cầu tính toán nặng dựa theo kiến thức vật lý và khoa học, thử luôn khả năng sinh văn bản dài có cấu trúc, upload thử tài liệu dài để nó phân tích và trả lời, khả năng sinh code dài,…. qua đó gần như chúng ta thấy được rõ hơn mọi khía cạnh trong khả năng chạy AI local trên chiếc máy này.

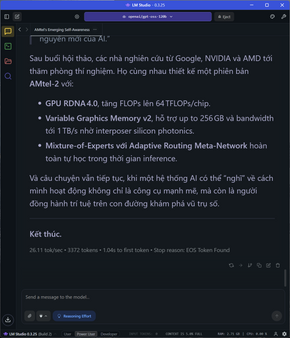
Nhìn chung, tốc độ decode trung bình ở chế độ không cắm điện đạt mốc 27 token/s, TTFT chỉ khoảng 1 giây, vẫn đảm bảo độ chính xác và suy luận tốt ở tất cả các task từ toán học cơ bản, logic, vật lý,… Đầu ra dài trên 5k token vẫn được duy trì ở mức 25-26 token/s mà không bị sụp. Cho bạn dễ hình dung, chỉ khi xài ChatGPT của OpenAI ở dạng gọi API thì tốc độ mới được cỡ 55 token/s, còn lại bình thường chỉ cỡ 8-10 token/s tùy lúc nếu xài ChatGPT trên web. Tốc độ của Ryzen AI Max+ thậm chí còn cao hơn tổng thể so với chạy model 120B tương tự trên Macbook M2 Max 96GB RAM.
Chi tiết hơn về trải nghiệm, tốc độ load model OSS 120B trên Ryzen AI Max+ rơi vào khoảng 50 giây. Đây là một con số khá nhanh nhờ vào khả năng gánh 120B 4-bit trên con iGPU của nó với Variable Graphic Memory (UMA tới tận 64GB). Như hồi chạy trên Mac M2 Max 96GB, tốc độ load cũng rơi vào tầm 46 giây.

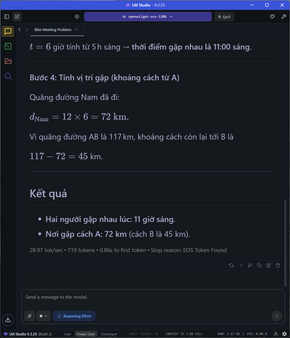
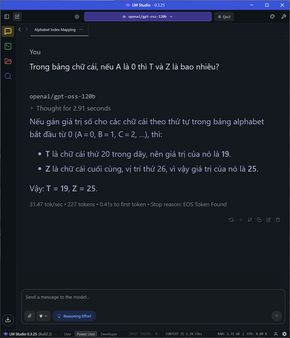
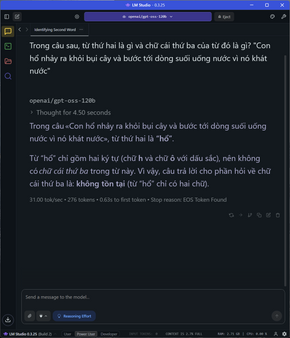
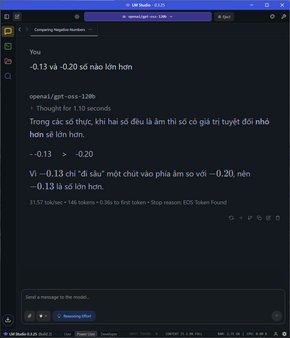
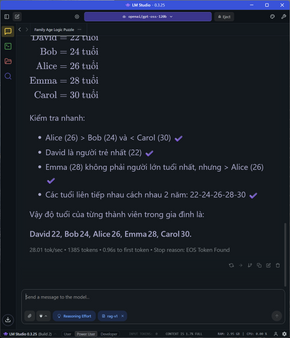
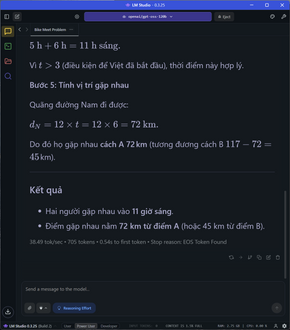
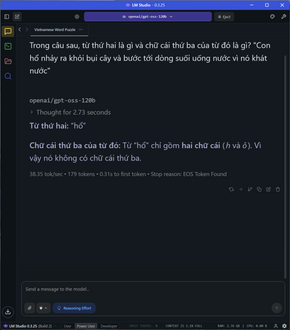
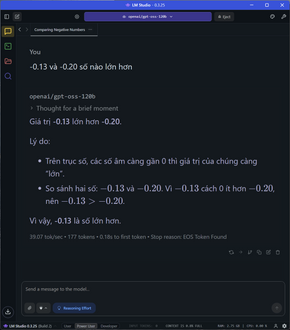
Đi sâu vào từng nhóm tác vụ, đói với các task đơn cử như so sánh số âm, các phép toán, so sánh số, bài toán đố đoán tuổi, xe đạp gặp nhau,…. tốc độ sinh sinh token dao động ở mức 28-31 token/s tùy tác vụ, thời gian TTFT cũng cực nhanh ở khoảng chưa tới 1 giây, latency cũng rất thấp.

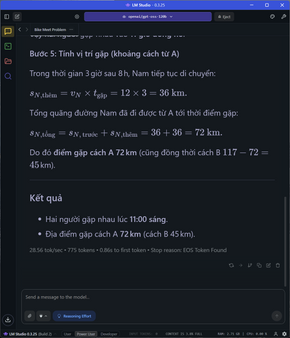
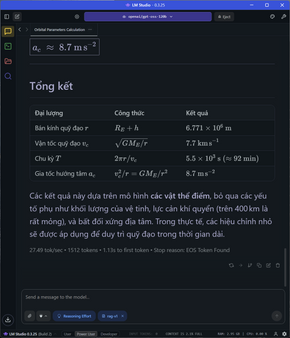
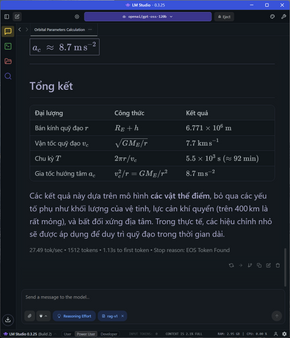
Đối với các bài toán phức tạp hơn, đòi hỏi nhiều bước tính toán như yêu cầu tính quỹ đạo cơ học, tốn gần 1500 token để giải quyết cả vấn đề, tốc độ vẫn ổn định ở mức 27 token/s và TTFT là 1.13s. Kết quả trả về vẫn chuẩn và chính xác, giải thích rõ ràng.
Quảng cáo

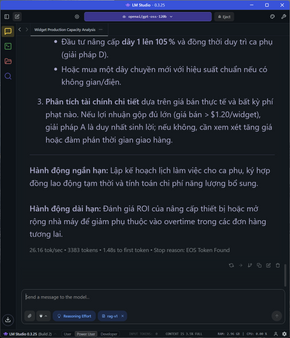
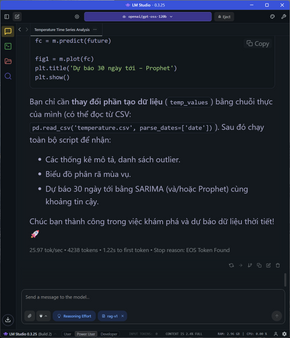
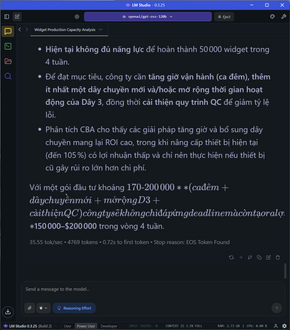
Thử đẩy lên tới một giới hạn khác, các task đòi hỏi tổng số token rơi vào từ 3300 đến hơn 5100 token như yêu cầu làm PRD một cái REST API phức tạp, phân tích và tối ưu công suất dây chuyền hoặc phân tích time series cho một tập dữ liệu (có code lẫn giải thích suy luận), tốc độ dù xuống 25-26 token/s và TTFT vẫn ở mức 1-1.4s nhưng vẫn là con số rất nhanh.

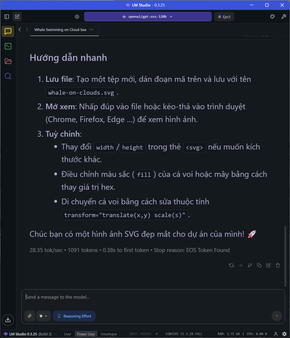
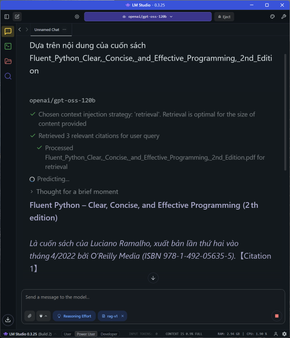
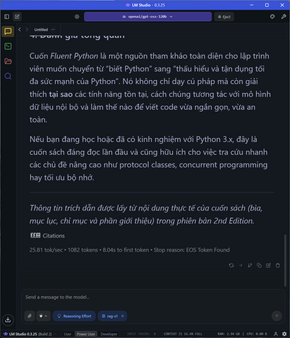
Ở task này, mình upload nguyên cuốn sách lên để AI nó ăn. Tất nhiên sẽ mất ít thời gian để LMStudio đi chunking, embedding rồi lưu vào RAG, sau đó tạo ra hơn 1000 token với tốc độ vẫn ổn ở 25 token/s.

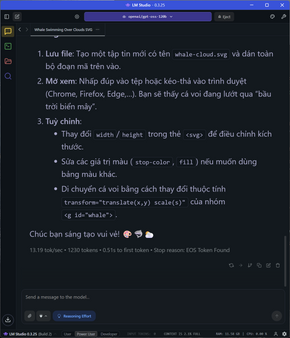
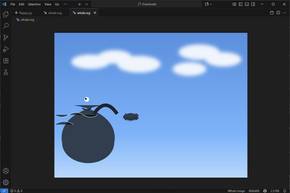
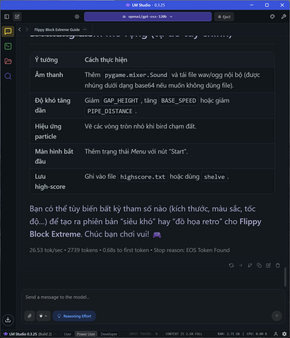
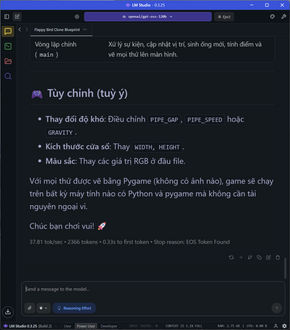
Thử kêu nó code python ra game flappy bird chỉ xài pygame, 2700 token được tạo ra với tốc độ ổn định ở 26 token/s.



Quảng cáo

Trong suốt quá trình inference, GPU chạy khoảng 82% với xấp xỉ 61-61/64GB bộ nhớ, xài thêm một ít từ 32GB RAM và GPU memory cỡ 63.1/96GB. Nhiệt độ đâu đó khoảng 63 độ C. Nếu để ý sẽ tấy CPU chỉ cahyj ở 6% cho thấy pipeline khi chạy LMStudio với engine Vulkan/DirectML vẫn tải chính ở GPU. Đặc biệt NPU vẫn không chạy do cơ bản task này vẫn chưa hỗ trợ NPU. Đặc biệt, 128 RAM luôn ở trạng thái gần như 100% khi AI suy luận, vắt nó để cho ra các tốc độ cao như bên trên. Và nên nhớ, đây là hiệu năng vận hành khi máy vẫn đang ở trạng thái chỉ dùng pin, không cắm điện. Toàn bộ quá trình test của minh từ lúc đầy pin, chạy full tải để thử nghiệm cho cả bài test này tốn khoảng 3 tiếng thì pin về 5%.
Hiệu năng chạy 120B OSS khi cắm điện
Mình thử cắm điện trực tiếp, load lại model 120B OSS ở trạng thái K quant cache (không ảnh hưởng tới weight của các layer) và lặp lại thử nghiệm một lần nữa. Lúc này con AMD Ryzen AI Max+ mới bung hết sức mạnh của nó ra. Tốc độ thực sự ấn tượng.

Kết quả chạy lại toàn bộ các task với prompt tương tự trong LMStudio, tốc độ dao động trung bình từ 36/39 tokens ở các task từ toán học, logic, sinh văn bản dài tới code. TTFT dao động từ 0.2 tới 0.5 giây, vẫn cực nhanh và ổn định.

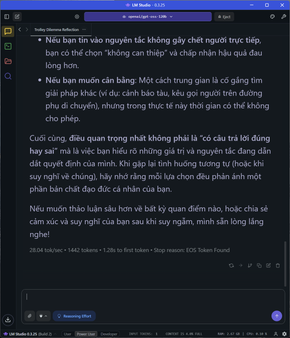
Lúc này, các tác vụ so sánh số, bào toán đoán tuổi, bài toán 2 xe gặp nhau, các câu hỏi logic hay lập luận dilemma được phản hồi với tốc độ cực kỳ cao, từ 37-39/s. Các bạn thấy nó sinh ra token nhanh khoảng gấp đôi về mặt thị giác so với khi xài ChatGPT 5 online.

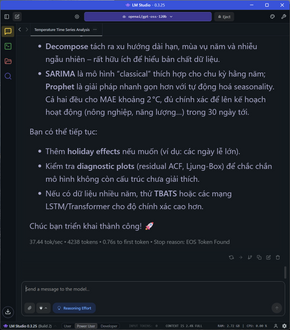
Các task phức tạp, sinh nhiều token và đòi nhiều bước suy luận hơn như game Flappy Bird, sinh file SVG, phân tích nội dung sách hoặc tạo hướng tiếp cận phân tích dữ liệu, tốc độ “giảm” xuống 36 token/s, vẫn là một tốc độ quá nhanh.
Nhìn chung nếu chạy một “con ChatGPT” nguồn mỡ mạnh nhất trên máy tính local của OpenAI, thì đây gần như là chiếc laptop / tablet mạnh nhất có thể làm được chuyện đó.




Làm thế nào AMD Ryzen AI Max+ 395 có thể đạt được tốc độ đó?
Đây là con chip 16 nhân 32 luồng được xây dựng trên kiến trúc Zen 5 với xung nhịp boost lên tới 5.1GHz, tích hợp GPU Radeon 8060S RDNA 3.5 với 40 Compute Units. Đồng thời chúng ta còn NPU kiến trúc XDNA 2 với khả năng tính toán tới 50 TOPS chỉ tinh riêng NPU. Con NPU này cho phép xử lý xử lý các toán tử phổ biến trong AI (matrix multiplication, attention, v.v.) với hiệu suất tốt so với chỉ dùng CPU/GPU tích hợp. Việc có NPU giúp giảm tải cho CPU/GPU, tiết kiệm năng lượng và độ trễ.

Một điểm ăn tiền chính là nó có 128 GB RAM unified memory, trong đó gần 96 GB có thể được dùng như VRAM (graphics-addressable hoặc cho các tính toán AI nặng), máy có khả năng xử lý các mô hình lớn hơn (LLM có tham số nhiều, hoặc inference/concurrent tasks) mà không bị “out of memory” (OOM) quá sớm.
Mặc khác do bản chất thiết kế, mọi thứ CPU, GPU, NPU và RAM đều ở rất gần nhau trên cùng một chip nên khi chạy các chatbot AI local, nó chăc chắn sẽ cho thời gian trả lời (time to first token) tốt hơn nhiều, tốt hơn cả sử dụng remote server hoặc online service. Mặt khác, bộ nhớ khủng khiếp tới 218GB RAM kết hợp với GPU+NPU+CPU mạnh còn cho phép máu chạy nhiều workload AI tốt hơn nhiều so với các hệ thống RAM nhỏ hoặc chỉ có GPU rời.
Dĩ nhiên, đó là chạy chứ mình đang không nói tới khía cạnh khác của AI là training. Nhu cầu training model AI lớn ngay từ đầu, cỡ 70B tham số trở lên hoặc fine tune dữ liệu lớn thì đây chắc chắn không là thế mạnh của con chip này. Mặt khác, bản chất là một con chip di động nên Ryzen AI Max+ vẫn sẽ bị giới hạn phụ thuộc về nhiệt, TDP và cả thiết kế hệ thống để tải nặng ổn định trong thời gian dài. Một yếu tố quan trọng khác, NPU cần được engine chạy AI hỗ trợ hiệu quả để khai thác tối đa vai trò của nó thì mới đẩy tổng thể hệ thống lên sức mạnh chạy AI hiệu quả nhất có thể.
Nguồn: Tinhte.vn


